

The B2B AI Journey: From Optimism to Reality
It’s been just over two years since OpenAI revolutionized the tech world with the release of ChatGPT on November 30, 2022. By January of the next year, it had already gained about 100 million active users, making it the fastest-growing consumer application in history.

Graph showing how fast iconic consumer facing tech platforms reached 100M users
Before its mainstream debut, AI technology was often perceived as a niche subject, primarily understood by researchers and data scientists. Now, two years later, it’s hard to find someone who hasn’t heard of AI. While some businesses are still debating whether to adopt the technology, the majority have at least started experimenting with AI tools and capabilities. In May of this year, McKinsey reported that 55% of respondents representing businesses globally have adopted AI in at least one business function.
Challenges with adoption
But as many of these companies have discovered, going from initial experimentation with GenAI (first pilot or POC) to deploying AI applications in production is far from simple. It’s relatively easy to isolate a structured data set, prompt, or dat sample, and show quick impressive results using publicly available models. This simplicity has enabled the rapid launch of numerous so called “AI wrapper” companies, built on models like ChatGPT-4 or similar models. In every industry vertical, these companies are able to showcase impressive and exciting demo’s, fueling the hype cycle in the business world that OpenAI initially ignited.
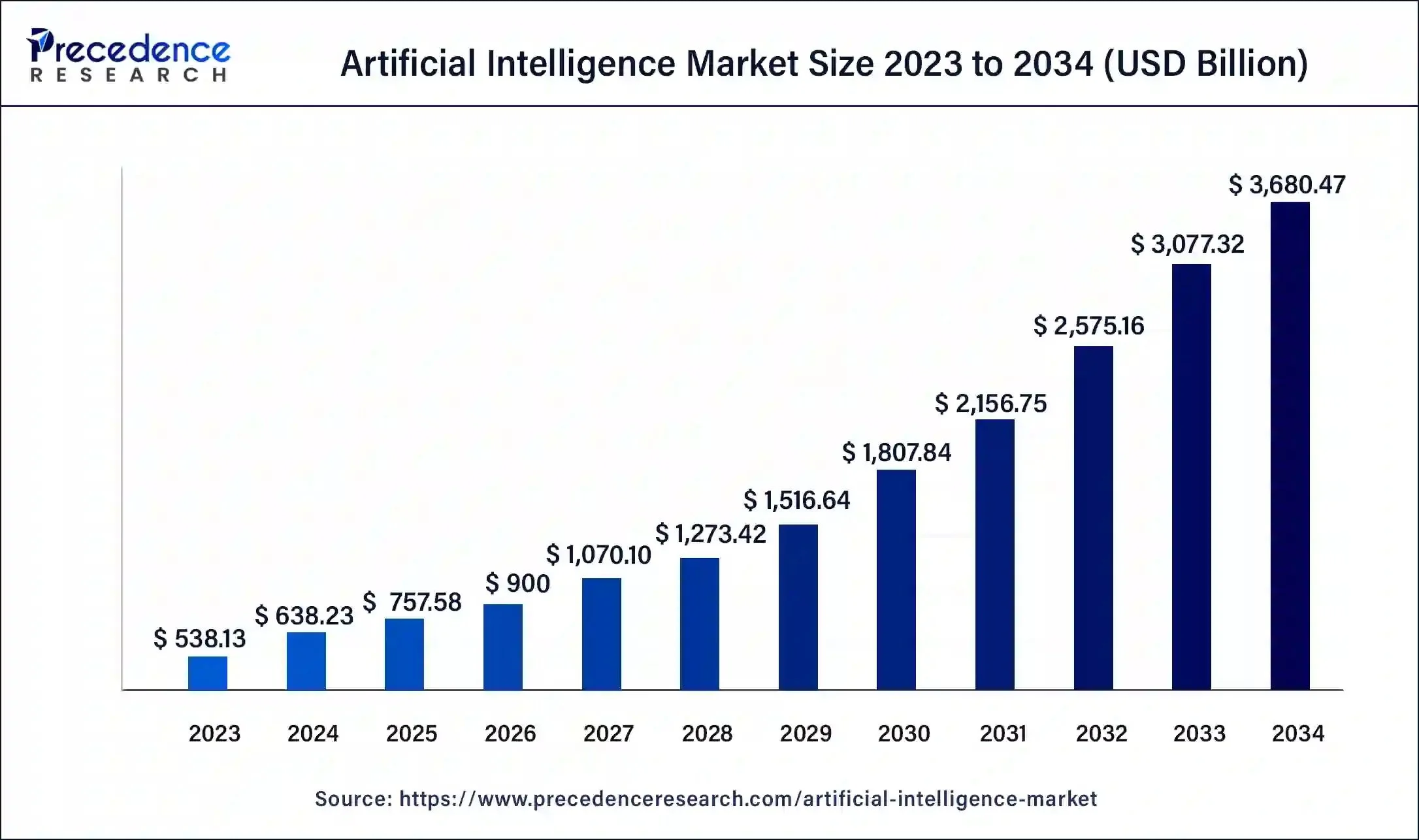
Graph from recent (Aug 24’) precedence research report on AI Market Size & Trends
The challenge is that in most cases, neither vendors nor clients know how to bridge the gap from pilot projects to large-scale AI deployments. Many vendors, having rushed to market, have yet to do extensive testing of their tools, while most clients lack the frameworks and testing environments. Dealing with vast amounts of both structured and unstructured data, along with issues like model hallucinations and accuracy challenges (such as embedding industry, or use-case specific heuristics) makes this process far more complex than a traditional code deployment.
Speaking of hallucinations, here are two of my favorite examples of why companies need to exercise caution when pushing customer-facing AI capabilities (like chat support) into production too quickly. In one instance, a car dealership’s chatbot mistakenly sold a Chevy Tahoe for $1. While no customer ultimately walked away with a $1 car, the incident highlighted the potential pitfalls of untested AI. In another case, Air Canada faced backlash when a customer successfully argued that the airline was responsible for a chatbot “hallucination,” which incorrectly promised a retroactive bereavement fare.
While model performance and accuracy seem to be some of the biggest factors slowing down the adoption of more AI within companies, we haven’t even started talking about Data Privacy & Security yet. Companies like Palo Alto Networks and Crowdstrike have been quick to develop cybersecurity tools and frameworks for AI security, and fast growing startups like Protect AI and PromptArmor are specializing in LLM security. Despite these advancements, for many infosec teams, data privacy and security in Generative AI remain a daunting “black box” problem. With foundational models constantly evolving and machine learning teams given free rein to experiment and develop new capabilities at the speed of light, it’s no surprise that the average infosec, and data compliance team struggles to keep up.

Reddit user commenting on their company’s approach to GenAI security
Fortunately, companies like OpenAI and others provide enterprise options that allow businesses to operate their own private LLM instances, promising that sensitive company data won’t be used for training purposes. But how private and secure are these solutions, really? Would you entrust them with personally identifiable information (PII), protected health information (PHI), intellectual property (IP), or other highly sensitive data? The reality is that your data must still pass through their systems to deliver meaningful value.
For now it seems that many companies are willing to turn a blind eye, operating under the mantra of “we’re following industry standards.” It’s more about having sufficient insurance to mitigate the fallout of a breach, with the mindset, “If something happens, we did our best to protect customer data.” However, if the decision were left to the average CISO, they’d likely sleep much better knowing their data remained securely on-premises.
On that note, I’ve encountered several companies deploying private LLM instances using services like AWS EC2 or managed solutions such as AWS Bedrock. While Bedrock simplifies access to foundational models with a high level of security, EC2 allows businesses to deploy and manage private LLMs on their own infrastructure within AWS. Both approaches aim to safeguard sensitive data but can quickly become prohibitively expensive. For instance, for just a small scale deployment, running advanced models on dedicated infrastructure can cost upwards of $50,000 per month.
This leads to another significant challenge in the current landscape of vertical vendors offering services built on foundational models: cost per token. While clients may not see these costs directly, vendors typically absorb the compute expenses. Each user interaction with an AI application (whether it involves sending a question, document, or file to the AI, or receiving a response from it) incurs a cost per token charged by the LLM providers. These costs can grow rapidly, depending on the model and the volume of tokens processed.
Looking ahead, it’s plausible that we’ll see an inverted graph: as LLM usage increases, cost per token is likely to decrease due to growing competition among providers. The entry of new contenders like Amazon, with its recently announced foundational model suite Nova, is expected to intensify this trend. Even so, vendors covering token costs on behalf of their clients are likely to see their margins shrink as product usage scales. Ultimately, someone (either the client or the vendor) will need to pay for it.

Basic cost per token comparison for different popular models, with average prompt example (100 in, 200 out). There are many publicly available comparison calculators out there, like this one from yourgpt.ai
Sidenote: Another intriguing challenge arises for companies that traditionally rely on human labor costs or billable hours as part of their business model. How do you bill your customers when you are using AI for most of the tasks that previously required human effort? Think of lawyers, accountants, freelancers, etc. It’s not just the vendors who need to reinvent themselves and their business models. Companies pricing their services based on human labor costs must also adapt. The idea of pricing based on time saved (namely by putting a price tag on the time AI saves someone from doing the work manually) can be difficult to sustain over the long term.
In production, and now?
So let’s say you’ve overcome all those hurdles; you’ve found a vendor that passes all your checks and balances, and you’ve successfully from an exciting proof of concept (POC) to an actual deployment of the tool or capability in your production environment. The next challenge is getting your organization to actually adopt the technology. This is a problem that many innovation teams and CIOs are focused on today.
In response, numerous trainings and workshops are being implemented, ranging from teaching employees how to write better prompts, to educating executive teams on best practices for risk mitigation and security. Retraining your workforce is a necessary step, and the sooner you start with it, the better. To do this effectively, your tech adoption teams must work closely with HR and operations. In larger organizations, this retraining effort requires a carefully orchestrated collaboration between multiple teams and leaders to achieve seamless implementation.
The reality today is that in most industries, employee adoption of AI tools and capabilities that have made it to production remains remarkably low. This may be due to vendors struggling to effectively integrate their tools into everyday workflows or simply the human tendency to resist radical change. Let’s face it; aren’t we all a little uneasy about the possibility that this powerful technology might one day take over our jobs?
For now it seems clear that the technology should be designed to augment (improve and speed up) human jobs, rather than replacing them. That said, augmentation often involves some level of automation, and the two concepts are not mutually exclusive. Many people mistakenly believe automation and augmentation are opposites, when in reality, automation is a key component of augmentation. The question is: what specific tasks and processes, currently handled entirely by humans, can be delegated to AI agents to enhance and augment human work? By doing so, organizations and their teams can achieve greater efficiency and productivity without eliminating the human element.
One company that stands out for effectively operationalizing AI to augment its workforce, is Lemonade Insurance. As their COO mentioned in a recent talk, GenAI is requiring COOs to rethink organizational composition and drive transformational change. The advantage for a company like Lemonade is that they have been designed around the concept of AI from the outset (both for internal operations and client facing interactions).
What stands out to me is the clarity and intentionality which they have integrated their AI-driven automation into their business model. By defining clear KPIs and setting ambitious goals, they continuously push both technological and human boundaries to propel the business forward. Moreover, the company’s culture is deeply rooted in the understanding that their success is rooted in the successful adoption of the technology.

Slide from Lemonade (LMND) recent investor day deck found on their website
Reality kicks in
In the past two years, the conversation between AI vendors and their customers has evolved from pitching co-pilots designed to assist with programming and other repetitive tasks, to workflow orchestration platforms powered by AI agents. Think of an AI agent as a large language model (LLM) programmed to execute specific tasks or a series of tasks. These agents can dynamically perceive, reason, and act to achieve outcomes within predefined parameters or “guardrails.” Crucially, these guardrails are managed and monitored by human agents to ensure alignment with business goals and ethical considerations.
AI agents hold immense promise, but the reality is that even if the technology is ready, the people, and more importantly the existing regime (political, social, psychological environment) under which these people operate requires a more deliberate and paced approach to change. A parallel can be drawn to Tesla’s autonomous driving: while the technology itself may be advanced, its adoption is constrained by human behavior, regulatory frameworks, and cultural readiness.

Tesla’s Full Self-Driving (FSD) interface. The technology went into Beta in Oct 2020.
Currently, the most common pattern of adoption for internal use involves starting with familiar and low risk applications, such as deploying private instances of ChatGPT for simple tasks like text summarization or email drafting. Companies fully operated by AI agents are still more of a futuristic vision than a present-day reality. While large enterprises are well positioned from a resource perspective to lead these advancements, it is more likely that the first fully autonomous, AI driven organizations will emerge from smaller, more agile entities innovating from the ground up. Just like Tesla entered the EV industry as a new innovator.
In the meantime, there’s growing discussion around the idea that many of the major AI companies may have exhausted most of the readily available high quality data for training large foundational models. As a result, we appear to be witnessing diminishing returns from scaling these models further by simply adding more data. However, this doesn’t mean we’ve reached the limits of what the technology can achieve for businesses. There’s still a robust foundation to build on (pun intended).
What it does mean is that we’re likely to see new approaches in model and system design. This includes models tailored to specific use cases and topics, enhanced context windows, and fine-tuning techniques. For instance, Meta recently launched LLaMA 3.3, a promising step toward more efficient models. By prioritizing quality over quantity, their new model aims to deliver more cost-effective yet highly accurate results, signaling a shift toward smarter, more targeted AI development. This recent talk with Satya Nadella is insightful if you want to learn more about this topic.
Concluding thoughts for businesses looking to offer AI solutions
As the initial wave of AI enthusiasm transitions to a more measured perspective, many organizations are reassessing their AI strategies. Early adopters who experienced overpromising and underdelivering are now focusing on establishing robust cultural, operational, and technical foundations to ensure successful AI integration across their enterprises. This shift is leading to a consolidation among vendors, favoring those with well-considered business models and seamless integration capabilities. Consequently, numerous overvalued “AI wrapper” companies are failing, creating opportunities for new entrants. It’s anticipated that the next generation of AI-first companies will adopt more competitive strategies, such as serving as horizontal enablers or offering verticalized end-to-end solutions, as discussed in a recent article by Andreessen Horowitz.
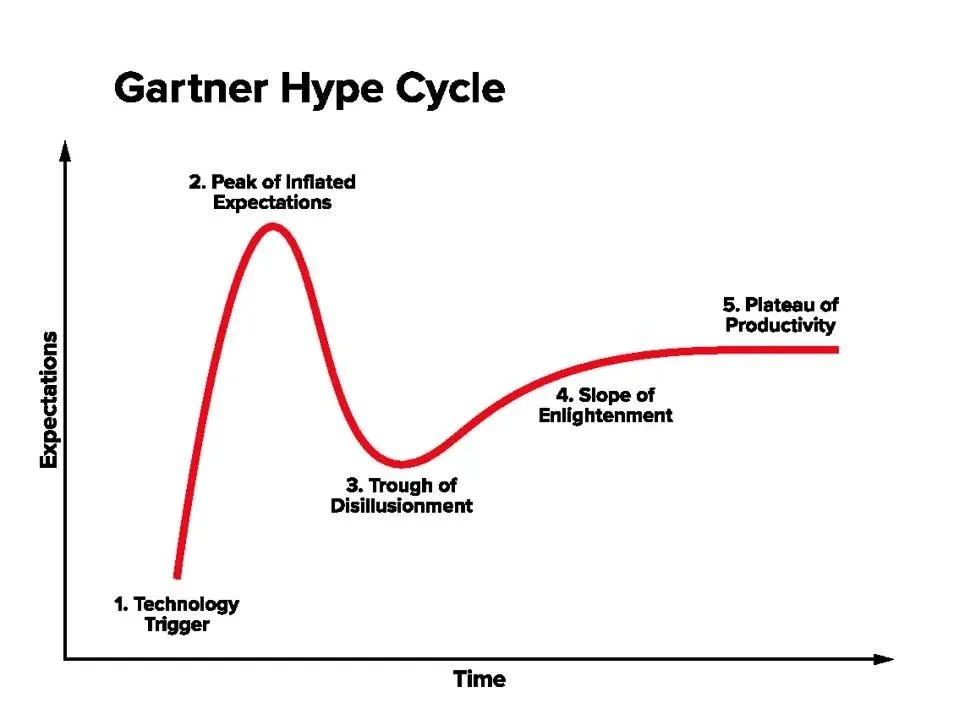
Gartner Hype Cycle graph. Might we be at or past the peak of inflated expectations?
Concluding thoughts for businesses looking to adopt AI capabilities
If your company hasn’t started experimenting with GenAI capabilities yet, it’s not too late. That said, now is the time to familiarize yourself and your staff with the tools and technology, even at a basic level. As you start, focus on quality over quantity and speed. Be pro-active.
There are countless articles and blog posts outlining the steps for successful AI adoption. While each has its own perspective, the overarching strategy is relatively straightforward:
Start by understanding your specific business needs and requirements (e.g. improving customer support, by increasing response time and accuracy of customer support emails).
Organize a team of one or more champions to spearhead your efforts. Ideally from different parts of the organization (including Operations, HR, IT).
Map out the current processes pertaining to the specific business needs, and understand what data is necessary to perform these processes in the most effective way possible (regardless if done by a human or by an AI agent).
Ensure that the necessary data is well organized and governed, so that any human or AI agent can easily and safely access it, and perform the associated tasks accordingly.
Analyze your options of augmenting the process, asking yourself if AI is actually needed for the optimization. Could it be done with simpler machine learning (ML) automation tools instead?
Assess your companies technical competency to orchestrate the necessary implementation. Can you build it yourself?
If not done in-house, list out what will be expected from a vendor providing the solution to you. Create a matrix for comparing vendors accordingly, before you select the most suitable one.
When selecting AI vendors, look for those who understand that there is no one-size-fits-all solution, and that it will take time and iteration to successfully deploy their solution with you. Rather than selling you an out-of-the-box solution, they should want to partner with you.
Final note
As a business owner in the AI space, I’ve spent the past 7+ months doing a deep dive into the topics of Data Management, AI agents, AI Governance, and many more. I love thinking about, discussing, and learning from other people’s perspective on all things related. Please do comment, DM, or contact me if you do too. I’d love to connect and have meaningful conversations with likeminded peers.
Thank you!
I want to thank all the people who have generously shared their time and experience with me in the past months of doing this deep dive. Pablo Ferrari, JW Beekman, Jacob Lee, Elaine Hankins, Ameya Naik, David Marco, Manrich Kotze, Kristen Sauter, Erik Beulen, Marla Dans, Lexie Ulven, Zineb Laraki, Kiran Gosavi, Adam Peltz, Thorben Schlätzer, Daniel Tapia Devia, Istvan Jonyer, Yvonne Tou, Mike Levy, Wendy Butler Curtis, Eric Johnson, Michiel Kalma, Juan Sanchez, Deepthi Chidirala, Hrishikesh Tiwari, Alison Bellach, Derek Stewart, Kevin Zhu, Siddhartha Mandati, Alexandra Johansen, Djon Kleine, Kathryn Bowman, Koen Van Wielink, Mike Nolet, Todd Conrad, Paul Potvin, James Milin, Pieter Verhoeven, Willem Roos, Don Yakulis, Mani Venkat, Syed Fiyaz, Landon Kelley, Philip Odence, Borzou Motlagh, Patrick Forrest, Andrew Hovanec, Ravi Kurani, Larry Rowland, Brennon York, Torben Fischer, Tom Redman, Lynn McAlister Rohland, Lwanga Yonke, Kewal Dhariwal, Mergan Kisten, Maia Zampini, Peter De Wit, Ana Pacios Escudero, Rachael Kim, Marco Hoppenbrouwer, Neer Ashash, Michael Hughes, Mark van der Straaten, Ari Letwin, Laura Sebastian-Coleman, Lizette Alvarado, Lauren Estevez, and the many others who have helped on this journey.